




The Transformer architecture has enabled the development of powerful AI models that can perform a wide range of tasks when combined with large amounts of data and computing resources. For example, GPT-3 can generate all kinds of text-based content like poetry or email responses, DALL-E can create realistic images from natural language descriptions, and BERT is an essential component of Google Search. With these advancements, artificial general intelligence (AGI) has become a tangible reality, fulfilling the ultimate goal of AI research.
Despite their impressive capabilities in understanding and generating text and images, current AI models have a major limitation – they lack the ability to take action in the digital world they operate in. This means that while they can process and analyze vast amounts of data, they cannot actually act upon it.
To address this limitation, the Action Transformer Model represents a groundbreaking leap in AI development, with the potential to have a tremendous impact on all areas of user activity. This model is designed to enable AI systems not only to understand and generate information but also take meaningful actions based on that information.
This article discusses the basics of the Action Transformer Model and its implementation details.
- What are the different types of artificial intelligence?
- Artificial Narrow Intelligence (ANI) / Weak AI / Narrow AI
- Artificial General Intelligence (AGI) / Strong AI / Deep AI
- Artificial Super Intelligence (ASI)
- What is a human-computer interface and its role in AI?
- What is an Action Transformer model?
- What can you do with an Action Transformer?
- Executing user requests
- Performing complex tasks
- Working in-depth on tools like spreadsheet
- Composing multiple tools together
- Searching information online through voice input
- Incorporating feedback
- How does an Action Transformer work?
- Input processing
- Intent recognition
- Action generation
- Execution
- Feedback and learning
- Security and privacy
- How to implement an action transformer?
- Data preparation
- Build the model architecture
- Train the model
- Model evaluation
- Tuning hyperparameters
- Use the model for prediction
- A case study on how LeewayHertz integrated the Action Transformer model
What are the different types of artificial intelligence?
Artificial intelligence is a field of computer science that aims to create machines that can replicate or even surpass human intelligence. By programming AI systems to perform tasks that usually require human intelligence, we can free ourselves from tedious and repetitive tasks and focus on other vital areas of work. AI systems can learn, reason, solve problems, and make decisions as humans do. And behind every AI system lies a set of powerful algorithms, such as machine learning, deep learning, and rule-based systems. Machine learning algorithms are fed with data, which then use statistical techniques to learn and improve their performance over time. As a result, AI systems become increasingly proficient at specific tasks without the need for explicit programming.
AI technologies are categorized by their ability to mimic human traits, their technology, real-world applications, and the theory of mind. We can classify all AI systems, whether existing or hypothetical, into one of these three types.

- Artificial Narrow Intelligence (ANI) has a narrow range of abilities and can perform a specific task exceptionally well.
- Artificial General Intelligence (AGI) is on par with human capabilities and can perform a wide range of tasks that require human intelligence.
- Artificial Superintelligence (ASI) is more capable than a human, making it a powerful tool that can transform various industries.
Let’s have an overview of these three types of AI.
Artificial Narrow Intelligence (ANI) / Weak AI / Narrow AI
Artificial Narrow Intelligence (ANI), also known as weak or narrow AI, is the only type of AI that we have successfully realized so far. Unlike the human brain, which can perform various complex tasks, ANI is designed to perform singular tasks with high intelligence and accuracy. Examples of ANI include facial recognition, speech recognition and internet searches. Although ANI may seem intelligent, it operates within a narrow set of constraints and limitations, hence the term weak AI. It doesn’t replicate or mimic human intelligence but simulates human behavior based on specific parameters and contexts.
The breakthroughs in ANI in the last decade are driven by advancements in machine learning and deep learning. These systems are used in medicine to accurately diagnose diseases like cancer and replicate human-like cognition and reasoning. ANI’s machine intelligence is powered by natural language processing (NLP), which enables it to understand speech and text in natural language and interact with humans in a personalized and natural manner. Chatbots and virtual assistants are examples of ANI technologies that use NLP to personalize interactions. ANI can either be reactive or have limited memory. Reactive AI can respond to different stimuli without prior experience, while limited memory AI is more advanced, using historical data to inform decisions. Most ANI uses limited memory AI and deep learning to personalize experiences like virtual assistants and search engines that store user data.
While ANI may seem limited in scope, it has demonstrated remarkable intelligence and accuracy in specific tasks. With advancements in machine learning and NLP, ANI is becoming more personalized and natural in its human interactions. ANI represents the first step in the journey towards more advanced AI and a world transformed by intelligent machines.
Examples of Artificial Narrow Intelligence (ANI) include Siri by Apple, Alexa by Amazon, Cortana by Microsoft, and other virtual assistants. ANI is also utilized by IBM’s Watson, image and facial recognition software, disease mapping and prediction tools, manufacturing and drone robots, email spam filters, social media monitoring tools for objectionable content, entertainment or marketing content recommendations based on watching/listening/purchase behavior, and even self-driving cars. These ANI systems excel at performing specific tasks with high accuracy and intelligence, but their abilities are limited to their programming and cannot replicate or mimic human intelligence.
Artificial General Intelligence (AGI) / Strong AI / Deep AI
Artificial General Intelligence (AGI) is another major AI research area scientists are focused on. AGI is also referred to as strong AI or deep AI and would enable machines to learn and apply their intelligence to solve any problem just as efficiently as humans can. Put simply, it can allow machines to replicate human intelligence and behaviors. However, achieving AGI is an enormous challenge, as it requires machines to possess a full set of cognitive abilities and the ability to understand human needs, emotions, beliefs, and thought processes. This is a significant step beyond narrow AI, which is limited to performing specific tasks within a narrow set of parameters.
The theory of mind AI framework, which is the ability of the human mind to attribute mental states to others, is a key component of hot cognition and is used in strong AI research to develop machines that can truly understand humans. The challenge in achieving this level of AI is that the human brain is the model for creating general intelligence, and researchers still have much to learn about how the brain works. Despite these challenges, there have been notable attempts at achieving strong AI, such as the Fujitsu-built K supercomputer. However, the human brain’s complexity means it is difficult to predict when or if strong AI will be achieved. Advances in image and facial recognition technology offer hope for the future of AGI research. As machines become better at seeing and learning, we may see significant progress toward achieving the ultimate goal of creating machines with the same level of intelligence and understanding as humans.
Artificial Super Intelligence (ASI)
Artificial Super Intelligence (ASI) is the ultimate goal of AI research and development, surpassing human intelligence and the capacity for self-awareness and creativity. ASI machines would be able to understand human emotions and experiences and have their own desires, beliefs and emotions.
Unlike Artificial Narrow Intelligence (ANI) or Artificial General Intelligence (AGI), ASI would be far superior to humans in every way, not only in areas such as maths, science and medicine but also in emotional relationships, sports, art, hobbies and other domains. This is because ASI would have an unprecedented capacity to process and analyze data and stimuli with significantly greater memory.
However, the idea of self-aware super-intelligent beings raises significant concerns, as they would have the potential to surpass human intelligence, leading to consequences that are still unknown. If ASI machines were to become self-aware, they would have the ability to think and act independently, potentially leading to ideas such as self-preservation. The impact of such a development on humanity and our way of life is unclear and has sparked debates on the potential benefits and risks of pursuing ASI research.
Launch your project with LeewayHertz
Unlock the full potential of AI with our Action Transformer model-powered solutions and apps
What is a human-computer interface and its role in AI?

Human-computer interface (HCI), also known as user interface (UI), refers to the point of interaction between a human user and a computer system. It encompasses all aspects of how humans interact with computers, including hardware design, software design, and the usability of computer systems. There are several types of human-computer interfaces, including graphical user interfaces (GUIs), command-line interfaces (CLIs), and natural language interfaces (NLIs). Each of these interfaces has its own strengths and weaknesses, and the choice of interface depends on the specific application and the users’ needs.
Among all these, NLI is used in AI applications, which allow users to interact with computers or other electronic devices using natural languages, such as spoken language or typed text. NLIs are becoming increasingly popular due to advances in natural language processing (NLP) and machine learning (ML) technologies. The goal of NLIs is to make human-computer interaction more intuitive and user-friendly. Rather than requiring users to learn specific commands or navigate complex menus, NLIs allow users to communicate with computers more naturally and conversationally, which becomes especially useful for users who are not technically proficient or have limited mobility.
NLIs can be implemented in various ways, including chatbots, voice assistants, and text-based interfaces. Chatbots are computer programs that simulate human conversation, typically using text-based interfaces. Voice assistants like Amazon’s Alexa and Apple’s Siri use speech recognition technology to interpret spoken commands and provide responses. Text-based interfaces like those used in search engines and virtual assistants allow users to type in natural language queries and receive responses.
One of the key challenges in designing NLIs is ensuring that the system can accurately interpret and respond to user input. This requires sophisticated natural language processing algorithms that can understand the nuances of language and respond appropriately. NLP techniques, such as named entity recognition, part-of-speech tagging, and sentiment analysis, are often used to extract meaning from user input. Another challenge in designing NLIs is maintaining user engagement and avoiding frustration. NLIs must be able to respond quickly and accurately to user queries and provide useful and relevant information. This requires careful design of the system’s user interface and sophisticated machine learning algorithms that can learn from user interactions and adapt to their preferences over time.
What is an Action Transformer model?
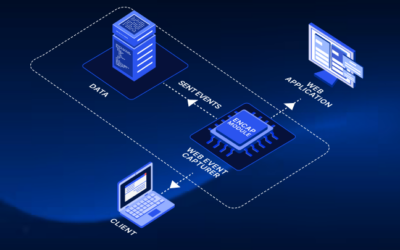
The Action Transformer Model represents a groundbreaking technological advancement that enables seamless communication with other software and applications, effectively bridging humanity and the digital realm. It is based on a large transformer model and operates as a natural human-computer interface, much like Google’s PSC, allowing users to issue high-level commands in natural language and watch as the program performs complex tasks across various software and websites. The ability of Action Transformers to process user feedback and continuously improve their performance makes them even more remarkable.
But what truly sets Action Transformers apart is their capacity to accomplish tasks that would otherwise be impossible for humans to perform. With their multitasking meta-learner capabilities, they can handle all sorts of software applications, making the need to learn Excel, Photoshop, or Salesforce obsolete. Instead, users can delegate these mundane tasks to the Action Transformer and focus on more intellectually challenging problems.
Of course, for Action Transformers to be effective, they must work flawlessly. If not, how can we trust them to accomplish tasks we lack the ability or knowledge to perform? Additionally, communicating with the model is crucial for success, highlighting the importance of prompting and clear instructions in the future of digital technology. Overall, the Action Transformer Model represents a significant step forward in human-computer interaction, offering unparalleled possibilities for innovation and progress.
Technically, the Action Transformer Model is an advanced artificial intelligence technology designed to serve as a natural human-computer interface (HCI) and enable seamless communication with other programs and applications. It allows users to issue high-level commands in natural language, which the program can then execute across various software tools and websites. The model is capable of handling tasks involving multiple steps and different software applications, making it a highly versatile tool. Additionally, the Action Transformer Model can learn from user feedback and continuously improve its performance, making it an increasingly valuable resource over time. Its ability to perform tasks that would be impossible for humans to accomplish is what sets it apart from other digital technologies. Overall, the Action Transformer Model represents a significant step forward in human-computer interaction and offers exciting possibilities for innovation and progress. The Action Transformer works by breaking down the user’s command into a series of smaller actions or steps that need to be performed. These steps are then translated into a sequence of API calls or other actions the system can execute. The tool uses a combination of pre-built workflows and custom logic to ensure that the actions it performs are accurate and complete.
What can you do with an Action Transformer?
Executing user requests
The Action Transformer Model is a groundbreaking artificial intelligence technology capable of performing a variety of tasks by communicating with different software tools. The model has been trained to understand natural language commands and can use its knowledge of different software applications to carry out complex tasks on behalf of the user by executing the necessary steps to complete the task. For example, if users want to create a spreadsheet that summarizes their monthly expenses, they need to type in a command such as “Create a spreadsheet summarizing my expenses for the month.” Action Transformer would then use its knowledge of spreadsheet software, such as Microsoft Excel or Google Sheets, to create the necessary spreadsheet and populate it with the relevant data.
Similarly, if a user wants to resize and crop a photo, they could type in a command such as “Resize and crop this photo” as a prompt. Action Transformer would use its understanding of photo editing software, such as Adobe Photoshop or GIMP, to execute the necessary steps to achieve the desired result.
Performing complex tasks
Action Transformer enables users to perform complex tasks by simply providing a natural language command. Using Natural Language Processing (NLP) and Machine Learning (ML) algorithms, Action Transformers understand the user’s command and translate it into a series of actions that a computer can execute sequentially to accomplish the task. For example, instead of clicking through multiple screens and menus to create a new contact in Salesforce, a user can type “Create a new contact for John Smith,” and the Action Transformer will execute the necessary steps to create the contact in the system.
Working in-depth on tools like spreadsheet
Action Transformers can automate tasks in various applications, including spreadsheets, which include a wide range of tasks, from simple calculations to complex data analysis. For example, instead of manually calculating the sum of a column of numbers in a spreadsheet, a user can type “sum column A,” and the Action Transformer will execute the necessary steps to perform the calculation. In this case, the Action Transformer breaks down the user’s command into a series of smaller actions or steps that need to be performed sequentially. The model then translates it into a sequence of API calls or other actions the system can execute. Also, the tool uses a combination of pre-built workflows and custom logic, ensuring that the actions it performs are accurate and complete.
Similarly, you can format, sort, filter, and perform calculations using Action Transformers in spreadsheets, saving time and increasing productivity. Besides, it can also help users perform tasks they may not know how to do themselves, such as performing complex statistical analyses or building interactive dashboards. Similarly, it can infer what the user means from context. For example, if a user types “average of the sales column,” the Action Transformer can infer that they want to calculate the average of the values in the column labeled “sales.” This ability to understand the context and infer user intent can help users perform tasks more quickly and accurately.
Composing multiple tools together
Action Transformer is capable of completing tasks that require composing multiple tools together. Most things we do on a computer span multiple programs, and the Action Transformer is designed to work seamlessly across multiple applications to complete complex tasks. For example, suppose a user wants to create a report that combines data from a spreadsheet, a database, and an analytics tool. Instead of manually copying and pasting data between multiple applications, the user can provide a natural language command to Action Transformer, such as “create a report that combines sales data from the spreadsheet with customer data from the database and visualizes it using the analytics tool.”
Action Transformer will then break down the command into a series of smaller actions and execute them across the various applications. It may use APIs, command-line tools, or other mechanisms to interact with these applications and extract the necessary data. One of the strengths of the Action Transformer is its ability to understand user intent and ask for clarifications when necessary. For example, if the user’s command is ambiguous or incomplete, the Action Transformer may prompt the user for additional information to ensure it can complete the task correctly, ensuring the final output is accurate and meets the user’s expectations.
In the future, we can expect Action Transformers to become even more helpful by leveraging advanced NLP and ML techniques. For example, it may be able to use context and previous user interactions to anticipate the user’s needs and provide suggestions or recommendations. Additionally, it may be able to learn from user feedback and adapt its behavior over time to meet the needs of individual users better.
Searching information online through voice input
Action Transformers can use a variety of techniques to look up information online, even when using voice input mode. Let’s say when a user provides a voice command to a tool using an Action Transformer, the model first converts the audio input into text using speech recognition algorithms and then uses NLP techniques to extract the relevant keywords and entities from the text, such as a person’s name or a specific piece of information that the user is looking for. Once the keywords and entities have been identified, the Action Transformer can use a variety of methods to look up information online. For example, it may use search engines, databases, APIs, or other online resources to retrieve the information that the user needs. Using pre-built workflows or custom logic, it ensures that the information it retrieves is accurate and relevant to the user’s needs.
Incorporating feedback
Action Transformer is designed to be highly coachable, meaning that it can learn from human feedback and become more useful with each interaction which is possible because the tool is built on machine learning (ML) algorithms that can adapt and improve over time as they receive more data. When an Action Transformer makes a mistake, it can be corrected with a single piece of human feedback. For example, if the tool misinterprets a user’s command or fails to complete a task correctly, the user can provide feedback to indicate where the mistake occurred and how it can be corrected.
The ML algorithms that power the Action Transformers can then use this feedback to adjust and improve the tool’s performance. The algorithms can identify patterns and learn from past mistakes by analyzing the feedback and comparing it to previous interactions. This makes the tool more accurate and reliable over time, ultimately making it more useful to the user.
One of the key advantages of this coachable approach is that it allows Action Transformer to adapt to individual users’ needs and preferences. As the tool learns from each interaction, it can adjust its behavior to meet the user’s needs better, making it more efficient and effective in completing tasks.
How does an Action Transformer work?
Action Transformer is a large-scale transformer model that uses Natural Language Processing (NLP) and Machine Learning (ML) algorithms to understand and execute user commands. Here’s a detailed overview of how it works:

Input processing
Input processing is a critical step in the workflow of an Action Transformer that involves analyzing and understanding the input provided by the user. Action Transformer is designed to process input in various forms, including text, voice, and structured data. For text input, the Action Transformer uses natural language processing (NLP) techniques to parse the input and extract relevant information, breaking down the input into individual words and analyzing the sentence’s grammatical structure to determine the meaning.
Action Transformer employs automatic speech recognition (ASR) techniques to convert the user’s spoken words into text when processing voice input. It then applies NLP techniques to analyze the text and understand the user’s intent.
For structured data input, the Action Transformer uses techniques such as data normalization and schema mapping to extract relevant information from the input and convert it into a format that the system can process. After processing the input, the Action Transformer applies its machine learning algorithms to generate an appropriate response or take action based on the user’s intent. The response may be in the form of text, voice, or a series of actions performed by the system.
Intent recognition
Intent recognition is a critical component of how an Action Transformer works. It involves identifying the user’s intent based on the input provided, such as a text or voice command. Here are the technical details on how the Action Transformer performs intent recognition.
The first step in intent recognition is preprocessing the input. This involves tokenizing the input into individual words, removing stop words, and stemming the words to their root form. After preprocessing, features are extracted from the input. This includes bag-of-words representations, which represent the frequency of each word in the input, as well as n-grams, which represent the frequency of combinations of words. The features are then used to classify the intent of the input. Action Transformer uses machine learning models, such as logistic regression, support vector machines (SVMs), and neural networks, to classify the input into different intent categories. Before classification, the machine learning model must be trained on a dataset of labeled examples. This dataset consists of input examples and their corresponding intent labels. As the Action Transformer receives new inputs and interactions, it can continuously improve its intent recognition capabilities by incorporating these new examples into its training data.
Overall, intent recognition in an Action Transformer involves preprocessing the input, extracting relevant features, classifying the intent using machine learning models, training the model on labeled examples, and continuously learning from new data. By performing these steps, the Action Transformer can accurately identify the user’s intent and generate appropriate responses or take action accordingly.
Action generation
After the Action Transformer Model has identified the intent of the user’s request, it generates a sequence of actions required to fulfill that request which can be broken down into several steps.
The model generates actions in two stages: instruction generation and code generation.
- Instruction generation: In this stage, the model generates high-level instructions for the program, such as the steps needed to achieve a specific task. The model inputs a description of the task, such as natural language text, and generates a sequence of instructions describing how to accomplish the task. For example, given the task of sorting a list of numbers, the model might generate instructions like “initialize a list variable,” “loop through the list,” and “swap the values of two elements if they are in the wrong order.”
- Code generation: In the next stage, the model generates actual code based on the instructions generated in the first stage. The model inputs the instructions generated in the first stage sequentially and generates a sequence of tokens representing the program code. The generated code is typically in a low-level programming language like Python or Java. For example, given the instructions generated in the first stage for sorting a list of numbers, the model might generate Python code that implements the sorting algorithm described by the instructions.
Execution
After generating a sequence of actions to fulfill the user’s request, the Action Transformer Model executes those actions on behalf of the user using an automation framework and by interacting with various software tools and applications, such as spreadsheets, databases, or APIs, by sending commands and receiving data in return. Furthermore, the execution process involves automating repetitive tasks, retrieving information from various sources, or performing complex calculations or analyses.
For example, if the user requests the model to extract data from a spreadsheet and perform some calculations on it, the model would first generate a sequence of actions to open the spreadsheet, extract the relevant data, perform the calculations, and then save the results. The model would generate code to execute these actions appropriately, with each step building on the previous one till the task is complete.
Feedback and learning
The feedback and learning mechanisms in the Action Transformer Model allow it to improve and adapt to the user’s needs continuously, making it an effective tool for automating tasks and simplifying complex workflows, which in turn helps improve its performance, making each interaction more useful and accurate. To accomplish this, the model collects feedback throughout the process, such as corrections to mistakes, suggestions for improvements, or requests for additional functionality.
When the user provides feedback, the Action Transformer Model adapts and learns from it. For example, if the model makes a mistake, the user can correct it, and the model will adjust its actions accordingly. Similarly, if the user suggests a better task performance, the model can incorporate that information into its future actions. The model also uses reinforcement learning to improve its performance by learning to identify which actions are most effective in achieving the user’s goal, involving a process of trial and error, where the model tries different actions and evaluates their effectiveness based on feedback from the user.
Security and privacy
Action Transformer takes several measures to ensure the security and privacy of user data. The model encrypts sensitive data, such as user inputs and outputs, to protect it from unauthorized access. Additionally, access controls are in place to restrict access to user data to only those individuals who require it to perform their tasks. Action Transformer also regularly conducts security audits to identify potential vulnerabilities in the system and takes prompt action to address them, mitigating the risk of data breaches and other security incidents.
Furthermore, the model adheres to relevant data privacy regulations, such as GDPR and CCPA, to protect user privacy. This includes obtaining user consent for data collection and processing, providing users with access to their data, and allowing users to request the deletion of their data.
Launch your project with LeewayHertz
Unlock the full potential of AI with our Action Transformer model-powered solutions and apps
How to implement an action transformer?
An Action Transformer Model is a type of machine learning model used to predict actions based on a certain input or context. It is often used in Natural Language Processing (NLP) tasks, such as machine translation, question answering, and dialogue generation, where the input sequence is first encoded into a fixed-size vector representation, and then the decoder generates the output sequence one token at a time, conditioned on the previously generated tokens and the encoded input.
Here are the general steps to implement an Action Transformer Model:

Data preparation
A crucial aspect of constructing an Action Transformer Model is preparing the data appropriately. The model requires data input in a specific format to operate accurately. The first step involves cleaning the data by eliminating irrelevant characters, symbols, and formatting, such as punctuation, special characters, and non-alphanumeric characters that do not contribute to the text’s meaning. Subsequently, duplicative or irrelevant data must be removed.
Afterward, the data is tokenized by breaking the text into smaller chunks, such as words or subwords, which is crucial since the model processes text as a sequence of tokens. Several libraries, such as the Python NLTK library, are available to tokenize text. Next, the tokens are converted into numerical representations that the model can process, typically by creating a unique token dictionary and assigning a unique index to each token. Each token sequence is then mapped to a sequence of numerical indices, which may have different lengths and can cause issues during model training. Padding can be added to the end of shorter sequences to make them the same length as longer sequences, and if a sequence is too long, it can be truncated to a specified length, ensuring that all input sequences have the same length.
Finally, the data is split into training, validation, and test sets, with the training set used to train the model, the validation set used to tune the hyperparameters, and the test set used to evaluate the model’s performance on new data. To improve the model’s performance and increase the training data size, data augmentation techniques such as random deletion, insertion, or replacement of words or phrases can be applied.
Build the model architecture
Building the model architecture of an Action Transformer Model involves defining the layers and parameters of the model. Several layers come into the picture. First, you need to build the input layer of the model that takes the numerical sequence of tokens as input. The input layer is typically an embedding layer that maps each token to a high-dimensional vector space. Next comes the encoding layer, consisting of a stack of transformer encoder layers that encode the input sequence into a fixed-size vector representation. Each encoder layer consists of a multi-head self-attention mechanism and feedforward neural network, followed by residual connections and layer normalization. To decode the information, the decoding layer consists of a stack of transformer decoder layers that generate the output sequence one token at a time, conditioned on the previously generated tokens and the encoded input. Each decoder layer consists of a multi-head self-attention mechanism, a multi-head attention mechanism with encoder output, a feedforward neural network, residual connections and layer normalization. Finally comes the output layer that takes the final hidden state of the decoder and predicts the probability distribution over the output vocabulary. The output layer is typically a softmax layer that computes the probabilities of the tokens in the output vocabulary.
Setting the hyperparameters is another crucial part that includes the number of encoder and decoder layers, the number of heads in the multi-head attention mechanism, the size of the hidden layers, the learning rate, the batch size, the dropout rate, and the number of epochs. These hyperparameters are usually determined by trial and error on a validation set to find the optimal configuration that minimizes the loss function.
Here are some additional tips on building the architecture of an Action Transformer Model:
- Using pre-trained embeddings can improve the performance of the model.
- Adding positional encodings to the input embeddings can help the model to understand the order of the input sequence.
- Using layer normalization and residual connections can help to prevent vanishing gradients during training and improve the model’s performance.
- Using a beam search decoding algorithm can improve the quality of the generated output sequences.
Train the model
Training an Action Transformer Model involves feeding the pre-processed input data through the model, computing the loss function, and adjusting the model’s parameters to minimize the loss function. Several steps are performed to train an Action Transformer Model, as described below.
- The training loop involves iterating over the training data for a fixed number of epochs. In each epoch, the model is trained on batches of data, where each batch contains a fixed number of input sequences and their corresponding output sequences. The batch size determines the number of batches per epoch, which is a hyperparameter of the model.
- Compute the loss function: The loss function measures the difference between predicted and true output sequences. The cross-entropy loss function is the most commonly used for sequence-to-sequence models. The loss function is computed for each batch of data, and the average loss across all batches is used to measure the model’s performance.
- Backpropagation and Gradient Descent: The backpropagation algorithm is used to compute the gradients of the loss function with respect to the model’s parameters. The gradients are then used to update the model’s parameters using the Gradient Descent algorithm. The learning rate is a hyperparameter that determines the step size for each update and can be adjusted during training to improve the model’s performance.
- Evaluate the model on the validation set: After each epoch, the model is evaluated on the validation set to measure its performance on unseen data, which involves computing the loss function and any other relevant metrics, such as accuracy or F1 score.
- Early stopping: Early stopping is a technique used to prevent overfitting by stopping training when the model’s performance on the validation set stops improving. This is typically determined by monitoring the validation loss over several epochs and stopping training when the validation loss starts to increase.
- Test the model: After the training is complete, the model is evaluated on the test set to measure its performance on unseen data. This involves computing the loss function and any other relevant metrics, such as accuracy or F1 score.
Model evaluation
After an Action Transformer Model is trained, evaluating its performance on a held-out test set is important. Several metrics are used to evaluate the performance of an Action Transformer Model:
- Loss Function: The loss function measures the difference between predicted and true output sequences. The lower the loss function, the better the model’s performance.
- Accuracy: Accuracy measures the proportion of correctly predicted output tokens in the test set. It is calculated as the number of correct predictions divided by the total number of predictions.
- F1 score: F1 score is a weighted average of precision and recall. Precision is the proportion of true positive predictions among all positive predictions, and recall is the proportion of true positive predictions among all true instances of the positive class. The F1 score measures the model’s overall performance, balancing precision and recall.
- Perplexity: Perplexity measures how well the model predicts the test set. It is calculated as 2^H, where H is the entropy of the model’s predictions on the test set. The lower the perplexity, the better the model’s performance.
- Bleu score: Bleu score measures the similarity between the model’s predicted output sequence and the true output sequence. It is calculated as a weighted combination of n-gram matches between the predicted and true sequences.
- Human evaluation: In addition to automated metrics, it is important to evaluate the model’s output. This involves having human evaluators rate the quality of the model’s output sequences based on fluency, relevance, and coherence criteria.
Overall, the choice of evaluation metrics depends on the specific task and goals of the Action Transformer Model. Combining automated metrics and human evaluation can provide a more comprehensive understanding of the model’s performance.
Tuning hyperparameters
Hyperparameter tuning can be time-consuming but critical for achieving the best performance out of an Action Transformer Model. The choice of hyperparameters can depend on the specific problem domain, and the search strategy should be tailored to the size of the hyperparameter space and the available computational resources.
The first step in hyperparameter tuning is to define the range of values for each hyperparameter which can be done based on prior knowledge of the problem domain or by using a range of values commonly used in the literature. The next step is defining the search strategy. Several search strategies can be used for hyperparameter tuning, including grid search, random search, and Bayesian optimization. Grid search involves exhaustively searching over all possible combinations of hyperparameters within the defined range, while random search involves randomly sampling hyperparameters within the defined range. Bayesian optimization uses a probabilistic model to iteratively explore the hyperparameter space and identify the most promising regions to search.
To evaluate the model’s performance for different hyperparameter settings, it is important to set up a separate validation scheme from the test set. This can be done using k-fold cross-validation or by setting aside a separate validation set. Next, for each combination of hyperparameters, you need to train the model on the training set and evaluate its performance on the validation set. This involves setting up the training loop, computing the loss function, performing backpropagation and Gradient Descent to update the model’s parameters, and evaluating the model on the validation set.
Select the hyperparameters that result in the best performance based on the model’s performance on the validation set. This involves comparing the performance metrics, such as accuracy or F1 score, for each combination of hyperparameters. Once the best hyperparameters have been selected, train the final model on the combined training and validation set, and evaluate its performance on the test set.
Use the model for prediction
The Action Transformer Model uses a combination of self-attention and feedforward networks to encode the input sequence and then generates the output sequence one token at a time, conditioned on the previously generated tokens and the encoded input. This process allows the model to capture complex patterns in the input sequence and generate coherent output sequences.
The first step in making a prediction is to encode the input sequence using the encoder of the trained model. This involves passing the input sequence through several layers of self-attention and feedforward networks, resulting in a context vector that summarizes the input sequence. Once the input sequence is encoded, the decoder of the model generates the output sequence one token at a time. The decoder takes the encoded input sequence as well as the previously generated tokens as input and produces a probability distribution over the vocabulary of possible output tokens. The token with the highest probability is selected as the next output token. At each step of the decoding process, the decoder is conditioned on the previously generated tokens, which means that the decoder considers the context of the previously generated tokens to generate the next token. This allows the model to capture long-term dependencies and generate coherent output sequences. The process of generating tokens continues iteratively until a special end-of-sequence token is generated or a maximum sequence length is reached. The output sequence can then be returned as the prediction of the model.
Some additional tips for implementing an Action Transformer Model include:
- Pre-training the model on a large dataset before fine-tuning it on a specific task can improve its performance.
- Attention mechanisms can help the model focus on relevant parts of the input sequence.
- Regularizing the model using dropout or weight decay techniques can prevent overfitting and improve its generalization performance.
Launch your project with LeewayHertz
Unlock the full potential of AI with our Action Transformer model-powered solutions and apps
A case study on how LeewayHertz integrated the Action Transformer model
The problem
A manufacturing firm with over 10,000 support tickets in its database and 1000 SKUs is currently encountering difficulties in determining the most valuable support tickets for newly generated leads from its website. To overcome this challenge, the firm is seeking the implementation of an Action Transformer (ACT) model that can analyze the incoming leads and identify the top three support tickets that can assist their sales team in securing deals. Once identified, the ACT model automatically adds these tickets to the CRM.
The solution
LeewayHertz has segregated the solution into three distinct steps:

Data collection and pre-processing
In the first step, the support ticket data is collected and preprocessed using tokenization, part-of-speech tagging, and entity recognition techniques to extract relevant information. Then, the OpenAI Embeddings API is used to convert each support ticket into a vector representation, which is stored in a database.
Lead analysis
In the second step, when a new lead is added to the CRM, pertinent information such as product interest, demographics, and lead message is extracted, and a summary is created using LLM. The cosine similarity between the lead’s summary and the support tickets in the database is then calculated to identify the top three support tickets that align with the lead’s product interest.
Digital agent module
In the third step, the Digital Agent module generates step-by-step instructions using a fine-tuned LLM on how to add the top three support tickets into the CRM. Another fine-tuned LLM is used to generate code for the steps outlined in the instructions. The Script Execution Framework then uses the code generated to integrate the top three support tickets with the CRM. The framework utilizes pre-written action transformer automation scripts, but custom scripts can also be generated based on the required action items.
Endnote
We can imagine being able to communicate with our devices through natural language, eliminating the need for complex graphical user interfaces and extensive training. This is the future that natural language interfaces powered by Action Transformers can bring. With these interfaces, anyone can become a power user regardless of their expertise, making implementing their ideas easier and working more efficiently. We will no longer need to waste time searching for documentation, manuals, or FAQs because models will be able to understand and execute our commands, freeing us to focus on more important tasks. AI-powered Action Transformers will revolutionize breakthroughs in drug design, engineering, and other fields by working with humans as teammates, making us more efficient and creative. This technology shift will bring about more accessible and powerful software, democratizing access to technology and paving the way for greater innovation towards AGI. So, let us embrace this future with open arms and look forward to a world where communication with our devices is natural, intuitive, and seamless.
Ready to leverage the Action Transformer Model’s capabilities? Schedule a consultation today with LeewayHertz’s AI experts and let us guide you through the transformative possibilities this powerful technology can offer for your business.
Author’s Bio


Akash's ability to build enterprise-grade technology solutions has garnered the trust of over 30 Fortune 500 companies, including Siemens, 3M, P&G, and Hershey's. Akash is an early adopter of new technology, a passionate technology enthusiast, and an investor in AI and IoT startups.
Start a conversation by filling the form
All information will be kept confidential.
Insights
Agentic AI for next-gen cybersecurity operations
Through ZBrain Builder, its proprietary agentic AI orchestration platform, LeewayHertz builds intelligent agents that complement its cybersecurity services, enabling adaptive defense mechanisms, compliance automation, and secure AI deployments.

Generative AI for Regulatory Compliance: Benefits, integration approaches, use cases, best practices, and future trends
Generative AI is reshaping the field of regulatory compliance by enhancing risk management, boosting operational efficiency, and improving compliance monitoring.

Agentic AI in marketing: Integration approaches, use cases, benefits, and implementation strategies
Agentic AI represents a fundamental evolution beyond generative AI, enabling autonomous systems to execute complex marketing workflows without human intervention.




